OpenAI 推出的最新語言模型 GPT-4 不僅能模擬人類生成各類文章,還具備自我評估和改進的能力。這種獨特的「自我反思」技術使得 GPT-4 在許多較高難度的測試中取得重要進展,表現提升了 30%。

GPT-4 系統是 GPT、GPT-2 和 GPT-3 的後續產物,由 OpenAI 推出。目前,它是最大的多模態模型,能夠接收圖像和文本輸入,並輸出文本。該系統利用深度學習技術,仿照人類寫作,使用人工神經網絡。
研究員 Noah Shinn 和 Ashwin Gopinath 在論文中指出:「我們研發了一種使 AI 代理能模擬人類自我反思並評估自身表現的創新技術。在完成各類測試時,GPT-4 會添加額外步驟,讓其能自行設計測試以檢查答案,找出錯誤和不足之處,並根據發現修改解決方案。」
A Self-Reflecting LLM Agent
Equips LLM-based agent w/
-dynamic memory
-a self-reflective LLM
-a method for detecting hallucinationsChallenge agent to learn from its own mistakes
-Evaluate on knowledge-intensive tasks
-Outperforms ReAct agentsPaper: https://t.co/URsJWbkwmj pic.twitter.com/WfNcPQvIs6
— John Nay (@johnjnay) March 23, 2023
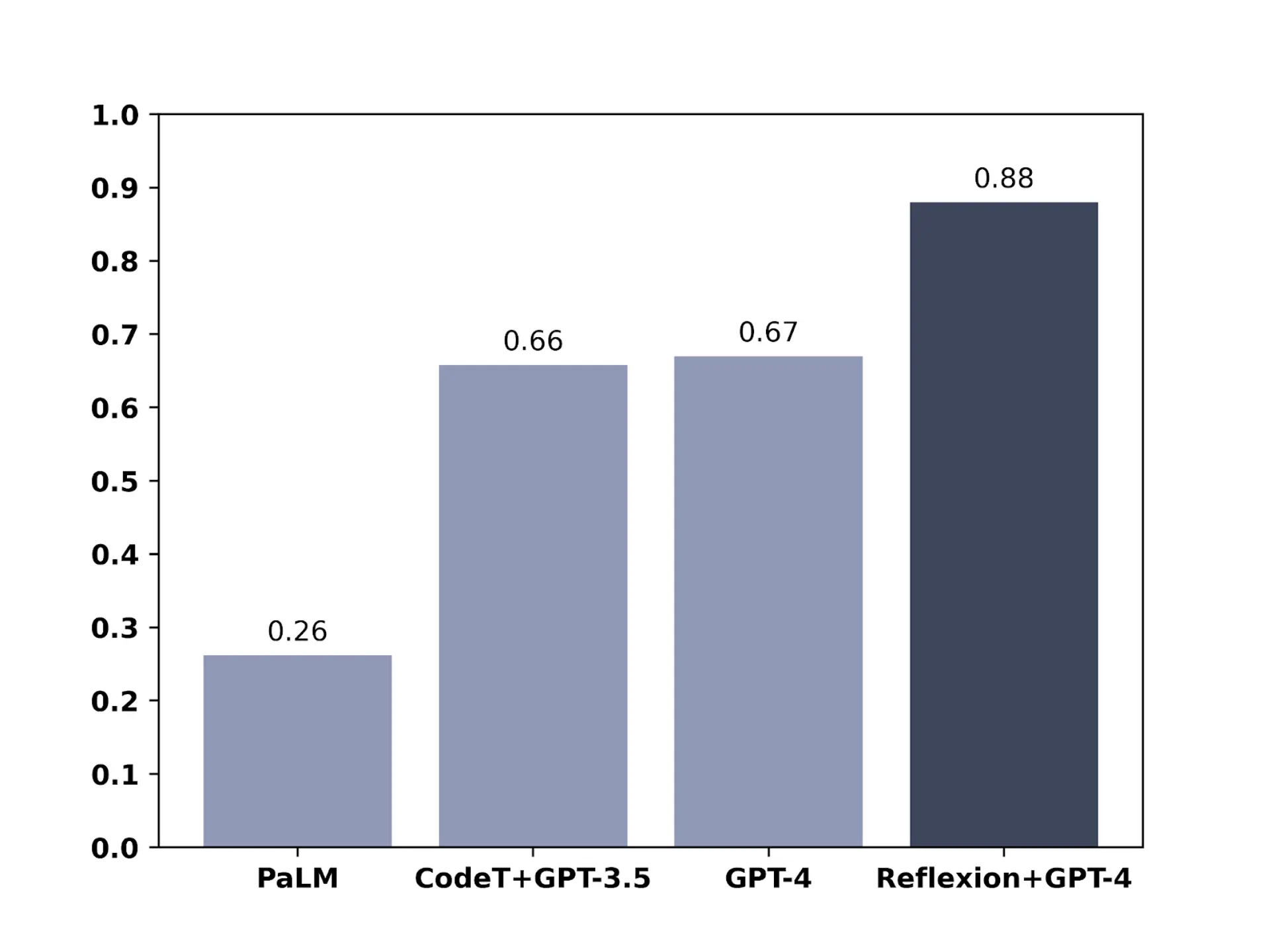
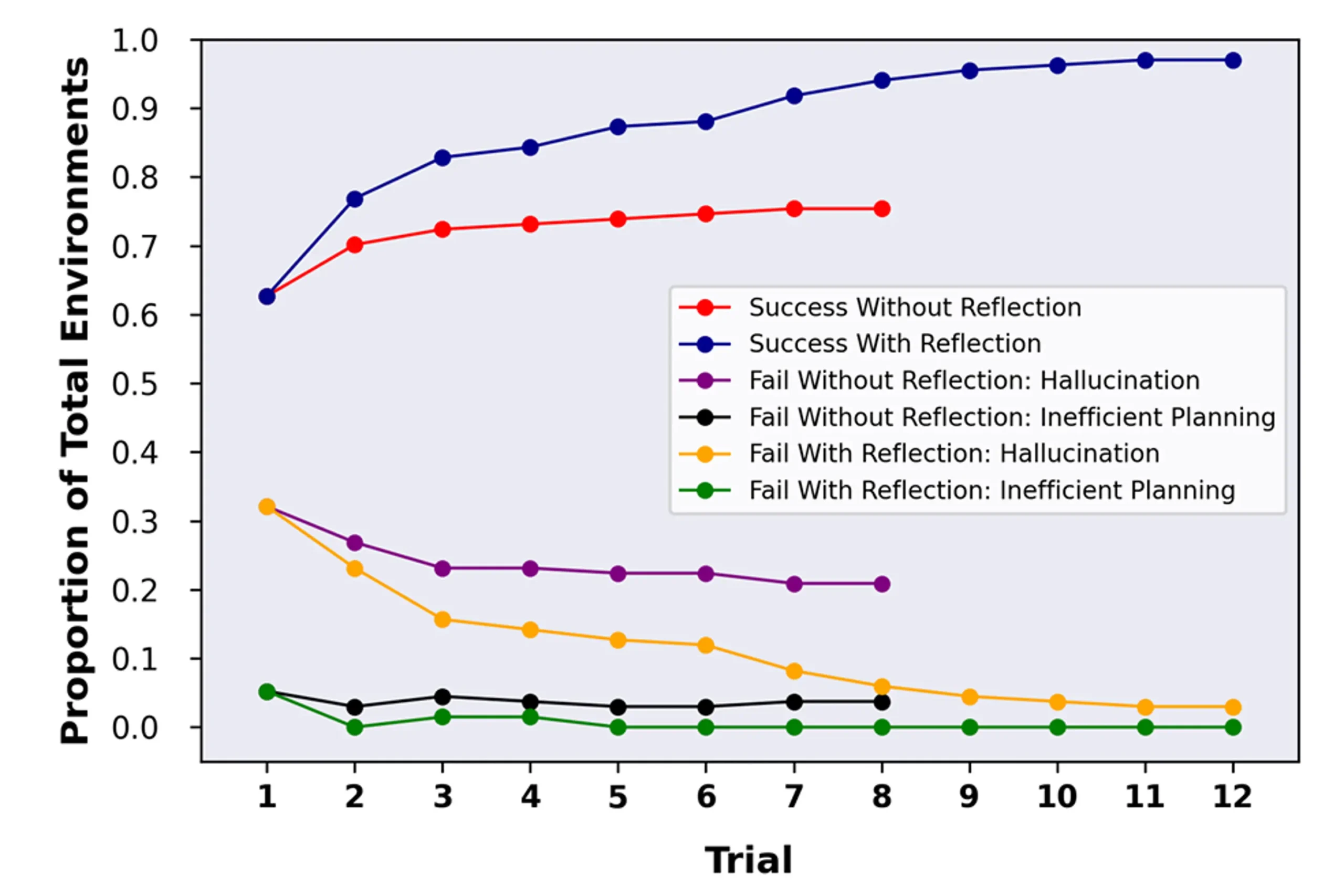
該研究團隊針對 GPT-4 進行了多種不同性能測試。在 HumanEval 測試中,GPT-4 面對 164 個未見過的 Python 編程問題,原本準確率為 67%;經反思技術後,準確率增至 88%。在 Alfworld 測試中,GPT-4 須在各種互動環境中進行決策,解決多步任務。應用反思技術後,準確率從 73% 提升至 97%,僅 4 項任務失敗。在 HotPotQA 測試中,GPT-4 可查閱維基百科,回答需從多個支援文件中解析內容並推理的 100 個問題。原本準確率為 34%,經反思技術後,提高至 54%。
此研究顯示,AI 解決方案有時依賴 AI 本身。這與生成對抗網絡相似,後者是讓兩個 AI 互相提升技能的方法。例如,一個 AI 嘗試生成看似真實的圖片,而另一個 AI 試圖分辨真偽。在 GPT-4 的情境下,它既是作者也是編輯,通過自我反思來提升自身輸出品質。











{kind=link}